

Denne høsten er det 25 år siden jeg fikk fast tilgang til internett. Jeg benytter anledningen til å mimre over gamle dager og gjør meg noen refleksjoner over datidens internett versus nåtidens.
Denne høsten er det 25 år siden jeg fikk fast tilgang til internett. Samme høsten fikk jeg også mitt første nettsted, eller hjemmeside som vi kalte det den gangen. Jeg husker godt frihetsfølelsen av å ha et sted som var mitt eget, hvor jeg selv bestemte hva jeg kunne skrive og mene. Den gangen fantes det ingen publiseringsløsninger, knapt nok verktøy for å lage hjemmesider. Det var knapt nok nettlesere, og jeg husker både Mosaic og de første Netscape-versjonene, som var forgjengerne til nettleseren vi i dag kjenner som Firefox.

I begynnelsen håndkodet jeg HTML til hjemmesidene med Notepad hjemme, lagret dem på diskett og tok med på «labben» der jeg studerte, hvor jeg lastet dem opp med FTP. Dette var på tiden før bredbånd og ISDN, og modem hjemme hadde jeg ikke ennå. Det er kanskje unødvendig å si at sidene hadde i overkant mange animerte GIF-er og lite innhold. På den tiden var det, foruten Notepad, kun to verktøy for å skrive HTML. HoTMetaL og HotDog. Senere kom også FrontPage som ble kjøpt av Microsoft.
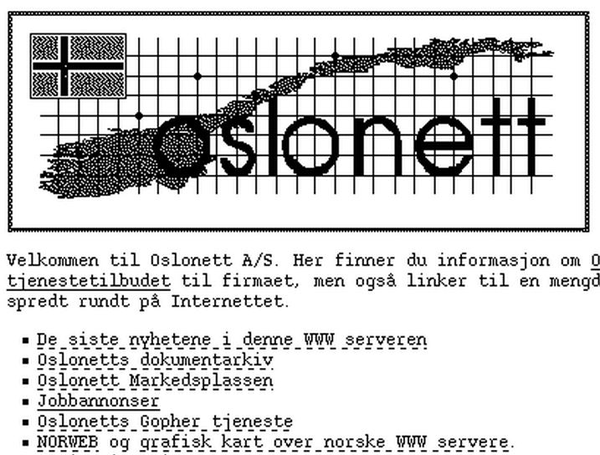
Ikke lenge etter fikk jeg tilgang til internett også hjemme, og ikke bare på studiestedet, via Oslonett som var Norges første tilbyder av internettjenester utenom akademia. Jeg var senere pilotkunde for ISDN hos Telenor, og bredbånd fikk jeg først da jeg flyttet til Oslo i 1999, med svimlende 0,5 mbit/s. Inntil da gikk det mye i disketter, Zip disks og CD-ROM. Her en skjermdump av Oslonett fra 29. juli 1994 via Kulturrådet:
I 1995 fantes ikke Google, de kom først tre år senere. En av de første ordentlige søkemotorene, AltaVista, kom først senere nevnte høst. Facebook var fortsatt tolv år unna, men vi hadde GeoCities og Usenet. Man kan kanskje ikke hevde at man savner GeoCities, men de hadde en viktig rolle i å gjøre publisering på internett tilgjengelig for folk. Usenet, eller news som det også ble kalt, savner jeg oppriktig. Det var desentraliserte og nærmest uregulerte diskusjonsfora uten administratorer og vilkår for bruk. Interessant nok var debattkulturen langt bedre på uregulerte Usenet enn hva man ser på Facebook og ymse kommentarfelt i dag.
I 1995 var heller ikke piratkopiering et begrep. Det dukket først opp for alvor med Napster i 1999, hvor samtlige plateselskaper lurte på hva pokker det var som traff dem. Strengt tatt tror jeg fortsatt ikke de forstår hva som traff dem, men de har om ikke annet forstått at så lenge de ikke selv gjør musikken sin tilgjengelig digitalt på lovlig vis, så vil piratkopiering være et problem. Sånn sett kan man si at The Pirate Bay, og teknologiene som der ble benyttet, tvang frem lovlige og brukervennlige distribusjonskanaler for musikk, film, bok, programvare og alt som kunne leveres digitalt.
Blogg var heller ikke et begrep. De første sakene jeg publiserte i 1995 kalte jeg «nyheter» og senere artikler. Med tiden kom også de første publiseringsløsningene, og før WordPress som jeg benytter i dag, benyttet jeg CuteNews. På den tiden var Movable Type en svært populær publiseringsplattform, men på grunn av endringer i lisensen migrerte mange til WordPress, og WordPress driver i dag noe slikt som hvert tredje nettsted på internett. Jeg har faktisk brukt WordPress siden versjon 1.0.
Begrepet «weblog» ble først unnfanget i 1997 og forkortelsen «blog» i 1999. Den gangen fantes det svært få blogger. Man kunne nesten telle dem på to hender, litt avhengig av hvilket miljø man vanket i. Jeg kan fortsatt navngi de første folkene som hadde blogger med innflytelse på det jeg selv skrev, men få av dem blogger i dag. Senere kom flere grupper seg på nett og tok eierskap til begrepet «blogging», og i dag er begrepet noe mindre positivt ladet, i hvert fall i mine ører.
I en nylig utgave av OBOS-bladet, skriver Ida Jackson klokt om internett før og nå, når hun i innlegget «Det digitale borettslaget» skriver at
Året var 2006 og jeg bodde i et parallelt univers der jeg kunne bygge hva jeg ville og skrive hva jeg ville og der de aller, aller fleste var snille. […] Etter hvert ble internettet jeg bodde på proffere og mer kommersialisert, det ble både mer vanlig og mer upersonlig. Og jeg ble en sånn person som hadde som levebrød å fortelle folk hvordan de burde internette bedre. Det var en helt fin jobb, men jeg følte likevel at de som flyttet inn med sosiale medie-strategier og annonsebudsjetter ikke helt hadde skjønt poenget. Internett var ikke en reklameplakat. Internett var et sted.
I 2001 kjøpte jeg domenet bekkelund.net, altså nettsidene du nå leser. Først og fremst fordi jeg ville eie mitt eget navn på internett, i stedet for å ha en tilfeldig adresse hos den leverandøren jeg til enhver tid benyttet. Domenet flyttet litt rundt hos forskjellige leverandører, men har i svært mange år vært i gode hender hos de dyktige folkene i Nordhost. Servicen deres er fantastisk og jeg har sågar vært på besøk i datasenteret hvor bekkelund.net driftes i Oslo. Da Microsoft lanserte sitt .NET Framework året etter, hadde jeg moro med å ønske Microsoft velkommen etter. Den gangen kunne ikke privatpersoner kjøpe .no-domener, uten at det var et savn. Internett er .net, liksom. I dag eier jeg noe slikt som 12 domener til forskjellige formål.
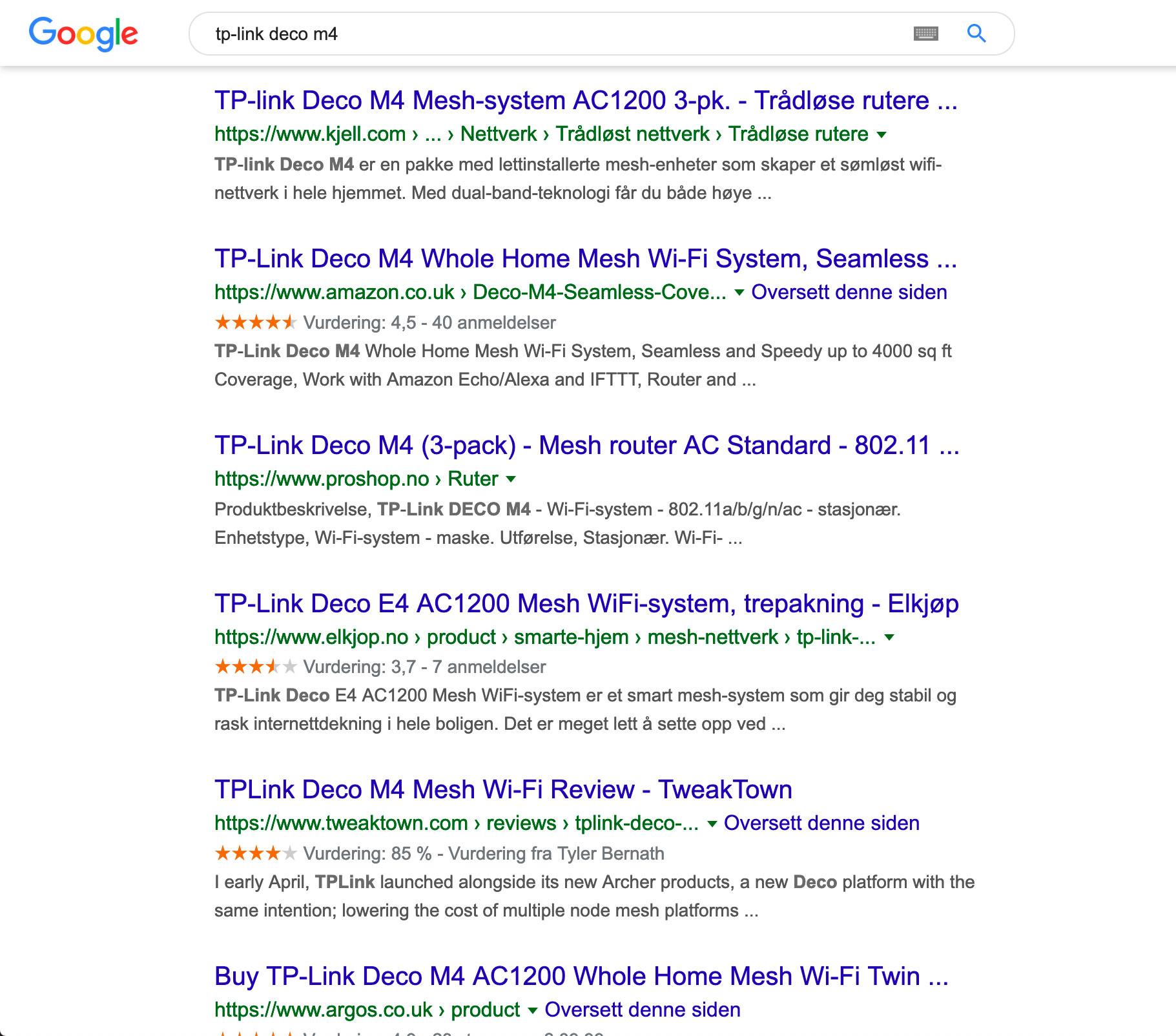
Det mest befriende med denne perioden på internett, var at den representerer det internett var ment å være: Desentralisert, åpent, nærmest uregulert og fritt tilgjengelig. I dag, derimot, er store deler av internett konsolidert i og regulert av plattformene til noen få aktører som for eksempel Facebook, Twitter, LinkedIn og Google. Det er dit du går for å være sammen med andre på nett og det er dit du går for å søke. De bestemmer hva du kan skrive og mene og, enda viktigere, de bestemmer hva du skal lese. Hvordan vet du egentlig at søkeresultatene til Google gir det som faktisk er de beste treffene for deg? Eller får du søketreff som sammenfaller med Google sine interesser for annonsering? Tilsvarende i nyhetsstrømmen din på Facebook og Twitter. En titt på følgende skjermbilde gir et visst inntrykk av hva som er viktigst, hvor et søk etter et produkt jeg ville lære mer om utelukkende ga annonsetreff på første side og produsentens nettsted først langt nede i søkeresultatene.
På den positive siden får du forhåpentligvis relevante søketreff og nyheter, uten at du kan si det med sikkerhet. Valget i USA ble påvirket av falske nyheter med kjøpt plassering. Hvor mye er man villig til å betale for å få relevante søketreff? Det er vanskelig å si, all den tid man ikke har full oversikt over hvor mye man faktisk betaler i form av personopplysninger. Jeg synes det er problematisk, og til tross for at jeg selv har konto både hos Google og Facebook og Twitter og LinkedIn, så er jeg svært bevisst på hvilke data jeg legger igjen der. Mest problematisk synes jeg min Gmail-konto er, og jeg har et langsiktig prosjekt om å migrere til ProtonMail.
Det siste tiåret har det blitt en kraftig konsolidering i antall plattformer, som nevnt tidligere. Svært mye informasjon publiseres på veldig få plattformer. Antallet plattformer står ikke i forhold til antallet mennesker med fast tilgang til internett. Facebook, LinkedIn, Twitter, Medium, WordPress.com og Patreon, for å nevne noen. Det betyr at plattformene fungerer som portvoktere, både med tanke på hva man kan skrive og mene, men også for hvordan plattformene fungerer teknisk og forretningsmessig. Det er problematisk at man kan påvirke så mye av demokratiet gjennom så få plattformer.
La meg ta et enkelt eksempel. Hos Google kan du som bedrift kjøpe annonser som blir vist til din relevante målgruppe på passende steder, for eksempel i søkeresultatene. Bedriften betaler for treff på bestemte søkeord. Hvis flere bedrifter byr på det samme søkeordet, er det bedriften som betaler mest som får treff først. Den bedriften som er villig til å bruke mest av overskuddet sitt i budrunden vinner kampen om søkeresultatet, men blir nærmest økonomisk årelatet fordi de betaler mye av overskuddet for å være først i søkeresultatene.
Apple faller i en litt annen og mer spesiell kategori. I motsetning til tidligere omtalte selskaper, er ikke Apple sin forretningsmodell å samle data om deg som selges til tredjeparter. Apple selger primært produkter og tjenester og har en helt annen strategi hvor de ivaretar ditt personvern på en bedre måte. Allikevel skal ikke Apple unntas fra kritikk, for selv om de har en god personvernstrategi, så er det fortsatt deres strategi å binde deg til deres plattform. Har du en iPhone? Hva med en Apple Watch? Og en Mac. Og en HomePod. Og så skal du selvfølgelig ha en iCloud-konto. Dette er selvfølgelig ikke unikt for Apple, det gjelder alle plattformer, enten det er Google eller Facebook eller LinkedIn. Oppsiden er at Apple er flinkere til å ta vare på mine data enn hva jeg selv er, nedsiden er at man blir avhengig av plattformen. I 2020 er jeg langt mer komfortabel med å ha mine data hos Apple enn for eksempel hos Google.
Et annet aspekt er hvordan mange gjør seg avhengige av en tredjepart eller plattform for å opprettholde sin inntekt. Hvis inntekten din er avhengig av plattformen, så har du et problem, for den som eier plattformen kan ta mer og mer betalt jo mer avhengig du er av den. Dette er mest synlig på plattformer som Patreon, Fiverr og tilsvarende. De som produserer og selger tjenester bygger seg opp historikk og evaluering fra sine kunder, men denne historikken og evalueringen er låst til plattformen. Skal man bytte plattform må man starte på nytt. Problemet er like aktutelt, men mindre synlig på andre plattformer der du som publiserer eller selger ikke er den som faktisk eier kundeforholdet. Trodde du at de som følger gruppen eller siden din på Facebook er dine kunder? De er først og fremst Facebook sine kunder, men du har tatt på deg jobben med å gjete dem for Facebook. Og skal du publisere noe på Facebook, så må du betale mer for å nå flere folk som du egentlig trodde var dine kunder.
Videre er det heller ikke slik at du selv har enerett til innholdet du publiserer på forskjellige plattformer. Ved å bruke plattformen gir du samtidig godkjenning til at eieren av plattformen nærmest kan bruke innholdet til det de selv ønsker. For det vesentligste vil det være snakk om å kunne skanne innholdet og bygge opp en profil over hva du benytter plattformen til, slik at de kan servere deg relevante annonser, men det kan også være i markedsføring av plattformen og selvfølgelig til å få tjenestene til å fungere. I Google sine vilkår står det rett ut forklart, her med min utheving:
Innholdet ditt forblir ditt, noe som betyr at du beholder alle immaterielle rettigheter du har til innholdet ditt. Du har for eksempel immaterielle rettigheter til kreativt innhold du lager, for eksempel anmeldelser du skriver. Eller du kan ha rett til å dele noen andres kreative innhold hvis vedkommende gir deg tillatelse. Vi trenger din tillatelse hvis de immaterielle rettighetene dine begrenser bruken vår av innholdet ditt. Du gir Google den tillatelsen via denne lisensen.
Et annet eksempel på at dine data ikke fullt ut er dine, er en strid som pågikk for et år siden mellom treningsnettstedet Strava og videogenereringstjenesten Relive. Man bruker førstnevnte til å registrere treningsøkter, for eksempel sykkelturer og kunne inntil striden benytte Relive til å generere en video av treningsøkten på Google Earth. Relive fungerte ved at de, med brukerens samtykke, koblet seg til Strava sitt API og hentet ut treningsøkter og genererte videoer. Strava mente den gangen at Relive sin bruk av API-et var i strid med vilkårene for bruk av API-et.
Min tolkning av striden er at Strava så at Relive sakte men sikkert utviklet funksjonalitet som nærmet seg Strava, og slik ble en konkurrent, og dermed kuttet av tilgangen til datagrunnlaget som Relive var avhengig av. De skriver det til og med i forklaringen til hvorfor de stengte Relive ute, her med min utheving:
These terms are in place to safeguard your personal information, to ensure a level playing field for all our partners, and to protect what makes Strava unique.
Hvis Strava hadde vært helt seriøse i sin påstand om at mine treningsdata er mine data, ville de latt meg bruke et hvilket som helst verktøy for å hente ut mine treningsdata, også konkurrerende tjenester. Relive var mitt verktøy. I virkeligheten, derimot, er mine data kun mine data innen det Strava mente var rimelighetens grenser. Strava fikk massiv kritikk for avgjørelsen, og jeg synes selv det var en flau strid for Strava. Nå må jeg selv laste ned en fil fra Strava og deretter opp til Relive for å generere video. Ja, det fungerer, men ikke mitt foretrukne valg og ikke enkelt nok til at jeg gjør det like ofte som før.
Det er disse årsakene som gjør at jeg fortsatt sverger til å ha kontroll over egne data og verktøy. Ikke for absolutt alle formål, selvfølgelig, men jeg har et bevisst forhold til hva som er viktig for meg. Nå selger ikke jeg produkter eller tjenester til deg som leser dette, men jeg liker å dele kunnskap og ideer og vil at mine lesere skal være mine og ikke ha et mellomledd mellom meg og deg som leser dette. Som leser kan du abonnere på nye artikler på e-post, og det er jeg som eier listen med e-postadresser og kan ta den med meg til en annen leverandør, dersom jeg er misfornøyd med Mailchimp som jeg benytter i dag. Du kan også abonnere på nye artikler med RSS.
Et annet fenomen som jeg synes er et av de mest problematiske på internett i 2020, er tjenester som sporer din aktivitet på tvers av nettsteder. Det finnes en diger skog, en uoversiktlig skog, av tjenester som samler inn data om ditt besøk på et nettsted og aggregerer informasjon om deg og skaper en profil over hvem du er og hva du er opptatt av, for så å kunne selge denne informasjonen til dem som måtte ha bruk for den. I mange tilfeller er det så mye data innsamlet at selv om ditt navn og e-postadresse og andre unike identifikatorer ikke er innsamlet, så kan dataene allikevel si nesten helt sikkert hvem du er, noe vi kommer tilbake til. Enda mer problematisk er at slike sporingstjenester også bygges inn i programvare du bruker på maskinen din. Ta for eksempel en titt på trafikken til og fra Spotify, så ser du at musikk ikke er det eneste de driver med. 13 tjenester utenom Spotify samler data. Tilsvarende med Adobe-produktene Photoshop og Lightroom. Et hett tips er å bruke Little Snitch til å blokkere slik traffik på den enkelte maskin og i tillegg ha en god brannmur som for eksempel Firewalla til blokkering på tvers av nettverket. Jeg har også skrevet om hvordan du ivaretar personvernet ved å bytte DNS, og med Firewalla kan du sette opp DNS over HTTPS mot Cloudflare.
Forbrukerrådet publiserte tidligere i år rapporten «Out of control», en av de viktigste rapportene på mange år, om hvordan annonseindustrien står bak omfattende brudd på personvernlovgivningen. Helt avhengig av hva man er opptatt av, selvfølgelig, men i denne konteksten tar den for seg omfanget av sporingen omtalt over. Omfanget er faktisk så stort at teamet som utarbeidet rapporten ikke klarte å få en fullstendig oversikt over hvilke data som ble innhentet, hvem som fikk tilgang til dem og hva de ble brukt til. Det er dypt problematisk at informasjon om meg selv blir brukt på måter jeg ikke kjenner til av bedrifter jeg ikke vet om.
Videre er ikke bare digital sporing et problem. Også fysisk sporing hvor apper samler inn og selger data om hvor du befinner deg har lenge vært et problem. Nylig gravejournalistikk fra NRK har gjort en utmerket jobb med å avdekke og vise for folk hvordan det foregår i praksis og omfanget av problemet. Det viser at det er viktig å lese vilkårene for bruk av tjenestene man tar i bruk, og ikke minst bruker tid på telefonen til å sette innstillingene riktig. NRKbeta har en artikkel om det siste. Det viktigste spørsmålet du stiller deg når du går igjennom listen over apper som skal ha tilgang til posisjonsdata, er hvorfor trenger denne appen dette? Hvorfor trenger appen til videoringeklokken min å vite hvor jeg er? I iOS skal utvikleren av appen skrive en kort forklaring på hvorfor appen trenger slike data, men forklaringen sier ingenting om hva dataene brukes til senere og hvem som får tilgang til dem. En god tommelfingerregel er å ikke tillate deling av posisjonsdata, med mindre det er noe av poenget med appen, og heller åpne for slik deling dersom det er påkrevet for at appen skal fungere.
Artikkelen til NRK viser nettopp poenget om at selv om det ikke ligger noen personidentifikatorer i datasettet, så er det allikevel mulig å identifisere enkeltpersoner ut i fra dataene. Selv tror jeg at jeg har god kontroll på posisjonsdata som forlater min telefon. Jeg vet i hvert fall hvilke apper som får lov til å samle denne informasjonen, men jeg har ingen uttømmende oversikt over hva disse appene gjør med dataene videre, slik reportasjen til NRK viser. Har du? Bare det å vite at jeg ikke vet synes jeg er foruroligende nok i seg selv, at «noen» kanskje besitter et komplett datasett over hvor jeg befinner meg til enhver tid. Sannsynligvis har jeg samtykket gjennom en obskur samtykketekst som man ikke forstår konsekvensen av, slik at selskapene som samler inn data har behandlingsgrunnlaget korrekt i henhold til lovverket, men om det er eksplisitt og tydelig, slik lovverket krever kan man jo stille spørsmålstegn ved.
En del tenker nok at «ja, ja, jeg driver jo ikke med noe spennende eller lyssky aktiviteter uansett, så det er ikke så farlig for meg», men jeg synes det blir for enkelt. Slik sporing fører med seg negative eksternaliteter, altså at det medfører store negative samfunnsøkonomiske kostnader eller konsekvenser utenfor hva en selv kan forestille seg. Snoking i data. Data på avveie. Data misbrukt. Slike ting, samt mye mer som heller ikke jeg klarer å forestille meg. I stedet for å tenke at slik sporing er greit, må argumentasjonen snus på hodet: hva er det legitime formålet for innsamling av slike data?
Tidligere direktør for Datatilsynet, Georg Apenes, har brukt et poeng med litt forskjellig ordlyd ved flere anledninger:
Når jeg går på toalettet, låser jeg døren. Men det er ikke fordi jeg har tenkt å gjøre noe ulovlig der inne.
Det er noen viktige prinsipper jeg synes har blitt svakere på internett anno 2020. Jeg savner det desentraliserte, åpne, nærmest uregulerte og fritt tilgjengelige internett.
Med desentralisert mener jeg fraværet av de store plattformene hvor svært mye publiseres i dag. Jeg savner bloggene man måtte bli tipset om og lete etter, i stedet for å henge rundt i grupper på Facebook eller følge folk på LinkedIn. Folk burde blogge mer og de burde gjøre det på sitt eget nettsted hvor man selv eier sitt eget publikum og sitt eget innhold. Det er en forkortelse som heter POSSE: «Publish (on your) Own Site, Syndicate Elsewhere». Det vil si at du publiserer det du har laget på ditt eget nettsted, og sprer det på de plattformene og måtene som passer for deg. Jeg er stor tilhenger av dette prinsippet. Publiser det på din egen blogg og spre det med e-post, RSS, på Twitter, Facebook, LinkedIn og hva vet jeg.
Med åpent mener jeg tilgjengelig for alle, uten at man trenger å registrere seg og godta et sett med brukervilkår for å få tilgang til det som er laget. Eller at man i det hele tatt trenger å godta noe som helst for å besøke nettstedet. Lese noe på Facebook? Du bør være bruker? Lese noe på LinkedIn? Du bør være bruker. Og så videre. Åpent betyr også bruk av åpne standarder som sikrer tilgjengelighet for alle, og ikke bare for dem som har en spesiell telefon, en spesiell nettleser eller et bestemt operativsystem. Dette er ikke et like stort problem som for 20 år siden, men den gangen var det et reelt problem med dominansen til Internet Explorer, og jeg deltok sågar i demonstrasjoner på 2000-tallet mot Microsofts forsøk på å få standardisert sine proprietære standarder.
Med uregulert mener jeg fraværet av vilkår for bruk av tjenestene man bruker for å publisere sitt innhold. Skal du publisere noe på Medium? Du må godta deres vilkår. LinkedIn? Det samme. Og for Facebook. Twitter. YouTube. WordPress.com. Selvfølgelig. Det skulle bare mangle. Hadde jeg eid en av disse tjenestene ville selvfølgelig jeg også stilt krav til dem som skulle bruke dem. Men ofte ser man at vilkårene også tar seg større rettigheter enn hva de trenger å gjøre, som for eksempel med eksempelet nevnt tidligere med at eierskapet ikke lenger bare er ditt eget. Jeg elsker at min ytringsfrihet og det du her leser kun er regulert av lovverket og mitt eget moralske kompass, og ikke av en tredjepart sine vilkår.
Med fritt tilgjengelig tenker jeg på flere ting. Det er en usynlig brikke i det store internett, som var helt vesentlig for å skape internett og som er like viktig for internett i 2020, og det er fri programvare. Fri programvare kunne jeg skrevet en egen artikkel om, men kort forklart er fri programvare egenskaper ved programvarens lisens som lar deg bruke programvaren slik det passer deg og ikke bare slik det passer den som har laget den. Last den ned, bruk den, endre den, forbedre den, dele den med andre. Det passer fint med prinsippene nevnt over med desentralisert, åpent, uregulert og fritt tilgjengelig.
Bloggen du nå leser er publisert med publiseringsløsningen WordPress. Fri programvare. Det samme er programvaren bak den, slik som databasen MySQL, operativsystemet Linux og programmeringsspråket PHP. Teksten jeg nå sitter og skriver gjøres i nettleseren Firefox. Også fri programvare, og ikke utviklet av noen av de store teknologigigantene, men et uavhengig selskap som deler de samme prinsippene.
Et annet aspekt av fritt tilgjengelig betyr at det ikke skal være noen barrierer for å få tilgang til noe på internett. Teksten du nå leser er fritt tilgjengelig for alle som har tilgang til internett. Jeg stiller ingen vilkår til deg som leser for at du skal få lese det. Videre skal det på den andre siden heller ikke være hinder hos deg som forhindrer deg fra å lese det jeg skriver, slik som statlig sensur, prioritering av visse typer trafikk eller tjenester, og tilsvarende hindre mellom meg som publiserer noe og deg som skal lese det.
Dette ble en mer dystopisk artikkel enn hva jeg hadde sett for meg. Kanskje fordi en del av den digitale utviklingen har gått i negativ retning. Men betyr det at alt er galt? Nei, det aller meste går heldigvis riktig vei, men det er unntakene jeg vier mye plass over og noen av dem er svært problematiske, slik som manipulering av valg, sporing både på og utenfor nett, samt noe av debattkulturen i kommentarfeltene.
Heldigvis er det meste bra på internett anno 2020. Internett brukt riktig virker demokratiserende og er tilrettelagt for fri deling av kunnskap. Internett er fortsatt åpent og alle kan mene hva de vil og dele og få tilgang til kunnskap. Piratkopiering opplever jeg ikke lenger som et problem, da de fleste har forstått hvordan de skal selge digitale produkter. Vi har fått mer profesjonaliserte løsninger både for å utvikle og drifte programvare, blant annet gjennom cloud-løsninger, det vil si standardiserte driftsløsninger som hjelper en med å bygge og sparer tid på driften. Selv bruker jeg DigitalOcean privat.
Internett er fortsatt ferskt, og vi har hatt den spede begynnelse og står nå i en mellomperiode, før jeg tror vi klarer å løse utfordringene nevnt over. Internett er desentralisert og anti-autoritært i sin natur, så jeg tror internett overlever det. Teknologien er allment tilgjengelig, både som fri programvare og kjente kryptografiske metoder for å beskytte data.
Kan det som ikke fungerer fikses? Ja, det kan fikses. Det kan fikses av deg og meg, men det krever en innsats av oss. Det krever først og fremst å forstå og være enig i det jeg skriver over. Det krever dernest at man bryr seg. Til slutt krever det at man gjør noe med det.
I neste omgang krever det også at det vi gjør er i tråd med prinsippene over, og at vi snakker med andre om dem og gjør dem bevisst på utfordringene med dagens internett.
Du kan jo starte med å dele denne artikkelen med dem du kjenner og som betyr noe for deg og som driver med et eller annet relatert til internett.
Gi et bidrag
Var denne artikkelen nyttig for deg? Som leser må du gjerne gi et lite bidrag. Jeg bruker mye tid og penger på å lage gode artikler og bidrag hjelper meg med å skrive flere. Bruk Vipps til nummer 800603 eller QR-koden, eller se andre måter å bidra på.

Husk å abonnere på nyhetsbrevet, det er gratis og du får alle artikler rett i innboksen.
Enda flere artikler? Besøk arkivet.
Martin Koksrud Bekkelund har arbeidet med teknologi og ledelse siden 1999, og er innehaver av konsulentselskapet Nivlheim. Jeg er friluftsmenneske og trives best ute. På fritiden er jeg opptatt av forbrukerteknologi. Les mer...








© 1995-2026 Martin Koksrud Bekkelund
Opphavsrett • RSS • Nyhetsbrev • Arkivet • Personvern og informasjonskapsler